Audio Reasoning
In late 2024, the first class of performant native audio models were released, with GPT-4o, Realtime Preview from OpenAI leading the pack. These models support direct audio input and output, a contrast from prior pipeline based approaches that would require audio -> text -> LLM -> text -> audio.
Via AragoAI, I worked with Artificial Analysis to develop a benchmark for assessing the performance implications of this new class of models. The benchmark, named Big Bench Audio ,highlighted that at initial release, there existed an Audio Reasoning Gap. GPT-4o (Aug '24) achieved 92% accuracy in the Text to Text version of the benchmark, while its Speech to Speech counterpart (GPT-4o Realtime Preview Oct '24) scored only 66% a near 30p.p performance degradation.
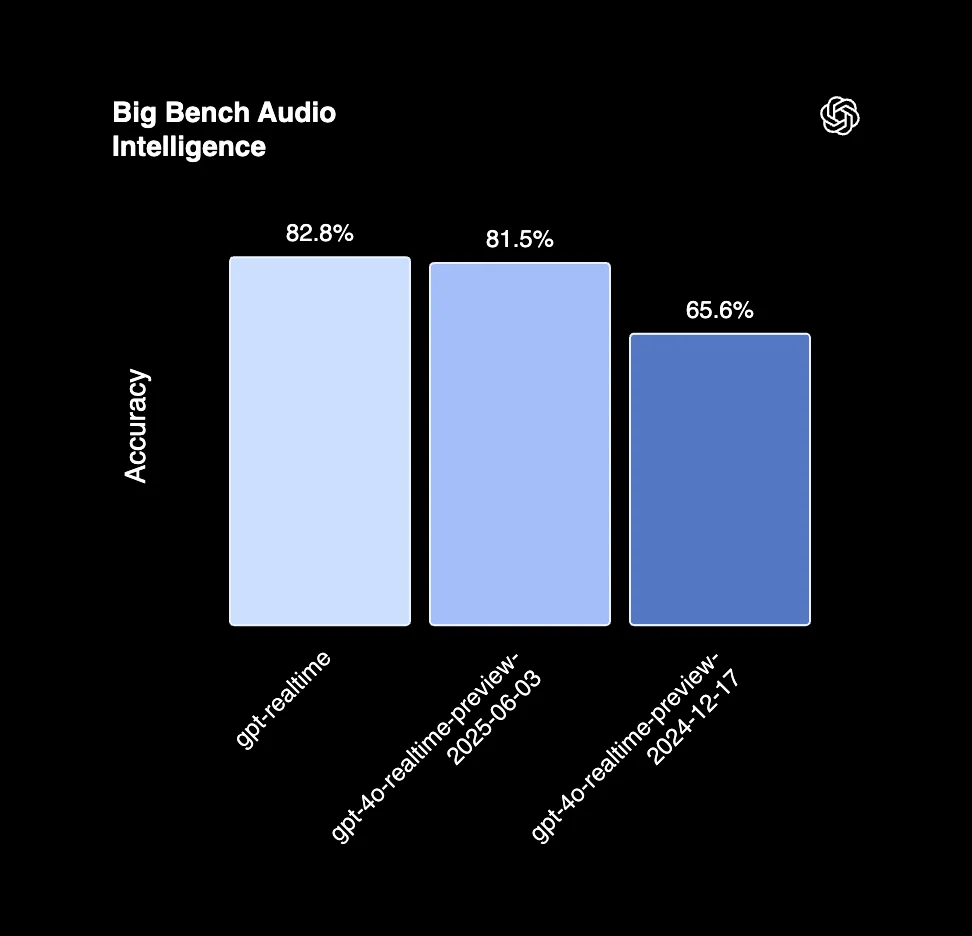
Throughout the course of 2025 native audio models have improved significantly. In August 2025, OpenAI released gpt-realtime and benchmarked performance on Big Bench Audio. As seen in their below release notes, this version offered a ~17p.p improvement on their prior native audio model.
gpt-realtime shows higher intelligence and can comprehend native audio with greater accuracy. The model can capture non-verbal cues (like laughs), switch languages mid-sentence, and adapt tone (“snappy and professional” vs. “kind and empathetic”). According to internal evaluations, the model also shows more accurate performance in detecting alphanumeric sequences (such as phone numbers, VINs, etc) in other languages, including Spanish, Chinese, Japanese, and French. On the Big Bench Audio eval measuring reasoning capabilities, gpt-realtime scores 82.8% accuracy—beating our previous model from December 2024, which scores 65.6%.
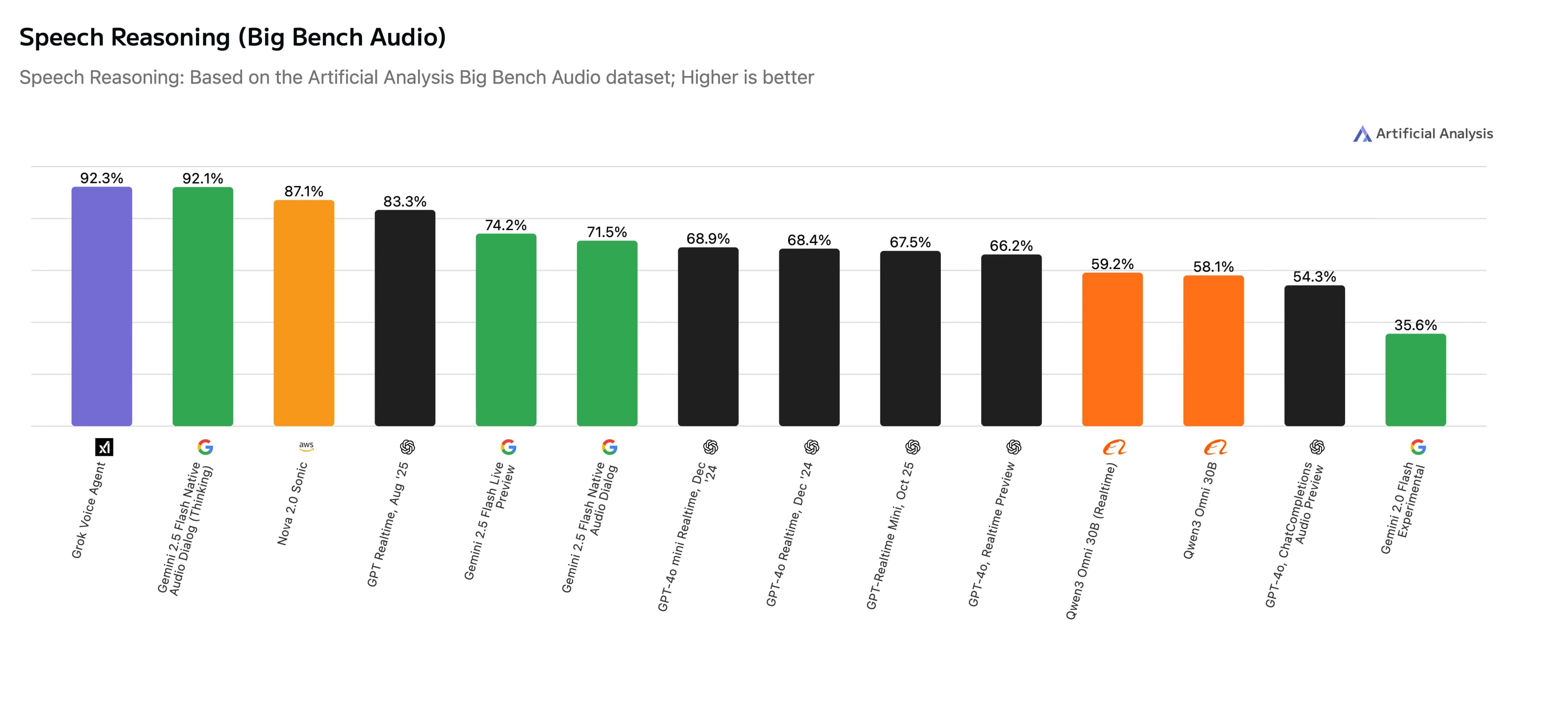
As at the end of 2025, xAI and Google lead performance with scores of ~92%. For a full analysis and additional details on the construction of Big Bench Audio, you can review the Speech to Speech page on Artificial Analysis' website. The dataset for Big Bench Audio has also been released publicly on HuggingFace.